
By Neil Majumdar, Data Engineer
Let me tell you about Data Vault. It is a data modeling methodology that promotes flexibility, data auditing, and fast loading. Data naturally includes history. Every record can be traced back to its source easily. New columns and tables can be seamlessly added to your model without messing with existing data. Most of this is based on just a couple of simple technical concepts.
I love it.
With that said, it also requires complex logic, is monstrously difficult to explain, and requires a lot of care when considering data relationships. It is not a model that should be used indiscriminately. Here at Yieldstreet, our data team uses a more traditional dimensional model for good reason.
As we built that model out, we faced the typical data challenges that crop up. Fact tables had to be scheduled around their dimensions. Incremental loads had to worry about backdated data. Typos from manual forms had to be dealt with.
Tauntingly, these are the challenges that Data Vault handles well. And if you look at why, it is due to just a couple of simple technical concepts. The type of concepts that could be added to our ETL with little fuss and without compromising our model.
In this blog post, I am going to tell you about two small but handy parts of Data Vault. While I am going to use a dimensional model for my examples, the concepts written here are agnostic to which design you are using. They are also dead simple. In fact you may have already used something similar in the past in some way or another. But in case you have not, let us talk about how to mix some Data Vault into your data model.
MD5
There is a famous quote from Bruce Lee floating around that goes something like this: “I fear not the man who has practiced 10,000 kicks once, but I fear the man who has practiced one kick 10,000 times”. If we are going to stretch this quote to apply to data models, and by golly am I going to try, then Data Vault has practiced MD5 hashing 10,000 times and mastered its usage. We can borrow some of those techniques in other data models in order to make reliable surrogate keys and track changes. Let me explain:
The MD5 hash is already used everywhere, not just in Data Vault. For data engineering purposes, it is often used to track changes in a table. Traditionally, you concatenate all of your columns together, apply an MD5 hash function to the concatenated string, and keep that MD5 output as a new column in your table. Now, when you next take data from a source, you can recalculate the MD5 hash and compare it to what you got the last time. If a row has a different MD5 hash than before, then you know something has changed and can proceed to add that row. For a SQL table, the calculation might look something like this:
SELECT
MD5(
CONCAT(
column_1,
column_2,
[,...]
)
) AS MD5_HASH
FROM ...However, there are a couple of instances where this runs into trouble. For instance, take this SQL table, WELL_LEDGER, famously used by Jack and Jill:
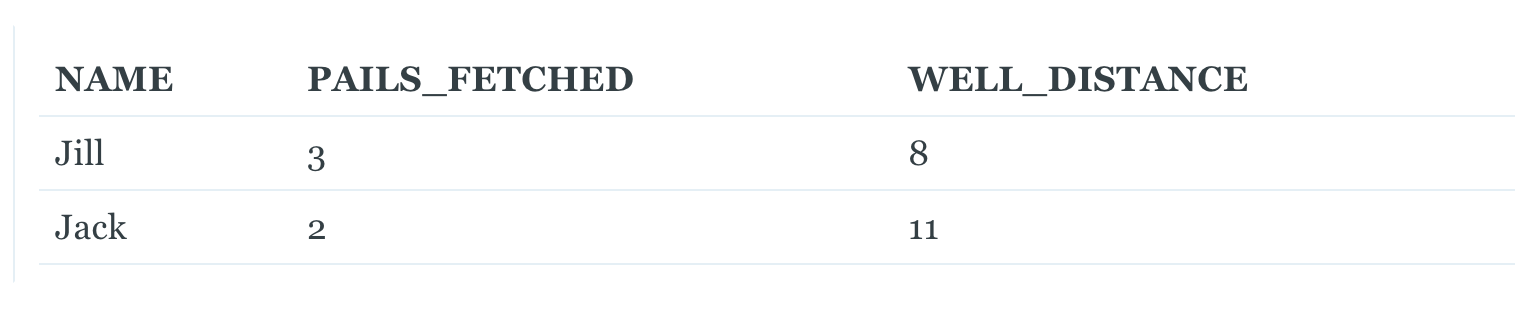
Each day, these two write down their names, how many pails of water they fetched that day, and how far away the well is. They simply overwrite the ledger each day with new values, so it is up to us to track changes. Now suppose the next day they write in this:
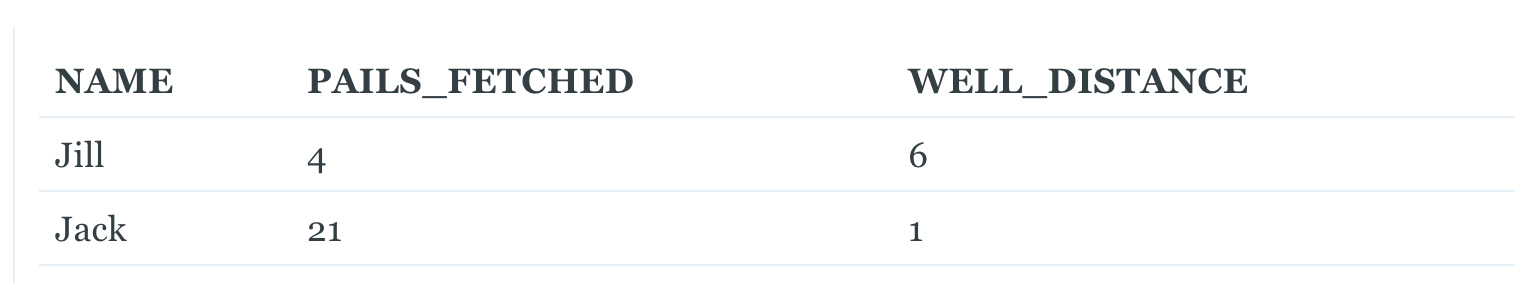
Take a look at Jack’s entry. If we run this through our MD5 calculation above, we will return the same MD5 hash for Jack as yesterday, since concatenating PAILS_FETCHED and WELL_DISTANCE will produce the string ‘211’ in both cases. Our process would then incorrectly conclude that there were no changes to his part of the ledger.
Let’s put a pin on that problem as we consider something else: If we wanted to make a dimension table out of the NAME column, how would we do that? One of the more common solutions is to use an IDENTITY column to create a surrogate key for NAME, then populate this table with the unique names. Something like this SQL could work:
CREATE TABLE D_USER (
ID BIGINT IDENTITY PRIMARY KEY,
NAME VARCHAR
);
INSERT INTO D_USER
SELECT DISTINCT NAME
FROM WELL_LEDGER a
WHERE NOT EXISTS (
SELECT 1
FROM D_USER b
WHERE a.NAME = b.NAME
);This will insert new names from WELL_LEDGER as they pop up, and they will be given a new BIGINT ID automatically. But now take a look at the next day’s WELL_LEDGER:

Jill took a break due to a minor head injury, so she couldn’t fetch her pails of water. Jack, without his sister double-checking his work, wrote both their names down in the ledger and made some typos. While we can reasonably guess who these names are referring to, our D_USER SQL certainly will not. Instead, we will have two new entries in our dimension table.
Moreover, take a look at Jill’s entry. We have a NULL value for PAILS_FETCHED and her WELL_DISTANCE was 46 meters away. Depending on how we concatenate, the output string will either be a NULL value, or will replace the NULL value with a blank string, resulting in an output like ‘46’. Again, we would have calculated the same MD5 hash as yesterday for Jill, leading to another false negative for detecting a change. Let's put a pin on these issues too as we consider a third problem.
We have a dimension table for names, so we might as well make a fact table for the metrics - PAILS_FETCHED and WELL_DISTANCE. To do that, we need the foreign key for D_USER in our fact table. What that often means is that we first load our dimension tables, so that they can create the ID field, and then afterward load our fact table. The SQL might be something like this:
INSERT INTO F_WELL_USAGE
SELECT b.ID as USER_ID,
a.PAILS_FETCHED,
a.WELL_DISTANCE
FROM WELL_LEDGER a
LEFT JOIN D_USER b ON a.NAME = b.NAMENote that this design leads to some slowdown on our data load. We have to load WELL_LEDGER first, then D_USER, then finally F_WELL_USAGE, even though the fundamental data we are trying to represent is all located in WELL_LEDGER alone. If we expand this out more generally, we are going to have to wait for all of our dimensions to load before we start loading facts, which introduces an extra ‘layer’ of our ETL schedule that doesn’t necessarily have to be there.
We’ve got enough pins collected now, so let’s summarize our three problems:
- Certain values for adjacent columns will cause our MD5 hash calculations to collide
- Our dimension table takes every unique value of NAME, turning some common typos into new records
- Our fact table has to wait for our dimension table to load first, slowing down our overall ETL timeline
It turns out that we can solve all of these problems at once by taking inspiration from Data Vault. First off, we are going to change how we calculate our MD5 hash:
SELECT
MD5(
UPPER(
CONCAT(
TRIM(
COALESCE(column_1, ‘NULL’)
),
‘|’,
TRIM(
COALESCE(column_2, ‘NULL’)
),
[...]
)
)
) AS BETTER_MD5_HASH
FROM ...You’ll notice a couple of things:
- We use a pipe delimiter between columns
- We add
TRIMandUPPERfunctions - We replace NULL values with a string value
With these simple changes, we can now turn to problem solving. With our new MD5 function above, our first problem is trivial. The pipe-delimiters will now ensure that adjacent columns will no longer produce the same hash for different values. Moreover, the COALESCE function will also ensure that NULL values are represented in our resulting hash.
Our second problem is that common typos will lead to a new key in our dimension table. Instead of relying on some auto-generated ID, such as IDENTITY, let us instead use the new MD5 hash to generate our IDs. Because our MD5 hash uses UPPER and TRIM functions, we now correctly identify Jack’s mistyped entries as being the same underlying person. Both ‘JAck’ and ‘Jack’ will resolve to the same ID, as will ‘Jill’ and ‘ JILL’.
Finally, our third problem is that we have to load dimension tables before fact tables. This is because the ID for a dimension is not deterministic - you have to see what the dimension table will produce for the ID and defer to that. However, now that we use an MD5 hash for our ID, the fact table can independently generate the MD5 ID from the source data. This means that the dimensions and facts can load in parallel and still arrive at a consistent result for ID.
Load Date
Data vault was designed with the ability to audit data in mind. Each record includes some metadata attached to it, and as that record gets transformed, that metadata is always included with it. We can pilfer this idea and apply it to our dimensional model as well.
I’m referring to a humble LOAD_DATE field, a timestamp that is generated for every row when it is processed into your data warehouse. It is generated once per batch of data, and we preserve this value as a row propagates through different tables. To see some of the benefits, let’s refer back to our aspiring data engineers, Jack and Jill.

Jack and Jill upgraded to a new WELL_RUN table. They keep track of each time they go to a well with their name and a time they record their run at. We have already loaded this table into our staging area and are ready to make dimensions and facts out of it. If we wanted to load that data from this table incrementally, we could do that fairly easily by keeping track of the RUN_TS. Every time data is loaded from this table, we can keep track of the maximum RUN_TS we found, and then during the next load we will only take rows with a RUN_TS higher than that. This is a pretty common practice for loading data. But take a look at this new record:
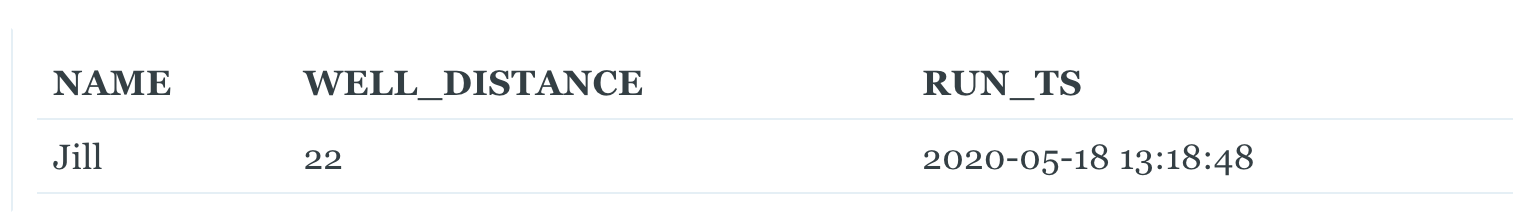
Jill forgot to record one of her runs, and added it in after we already loaded data up until June 3rd. The incremental process for our fact table will never identify this backfilled record since its RUN_TS is before our last saved value for RUN_TS.
Let’s consider something else as well. Suppose we’ve loaded this data into our dimensional model and have a fact table, F_WELL_RUN, like this:
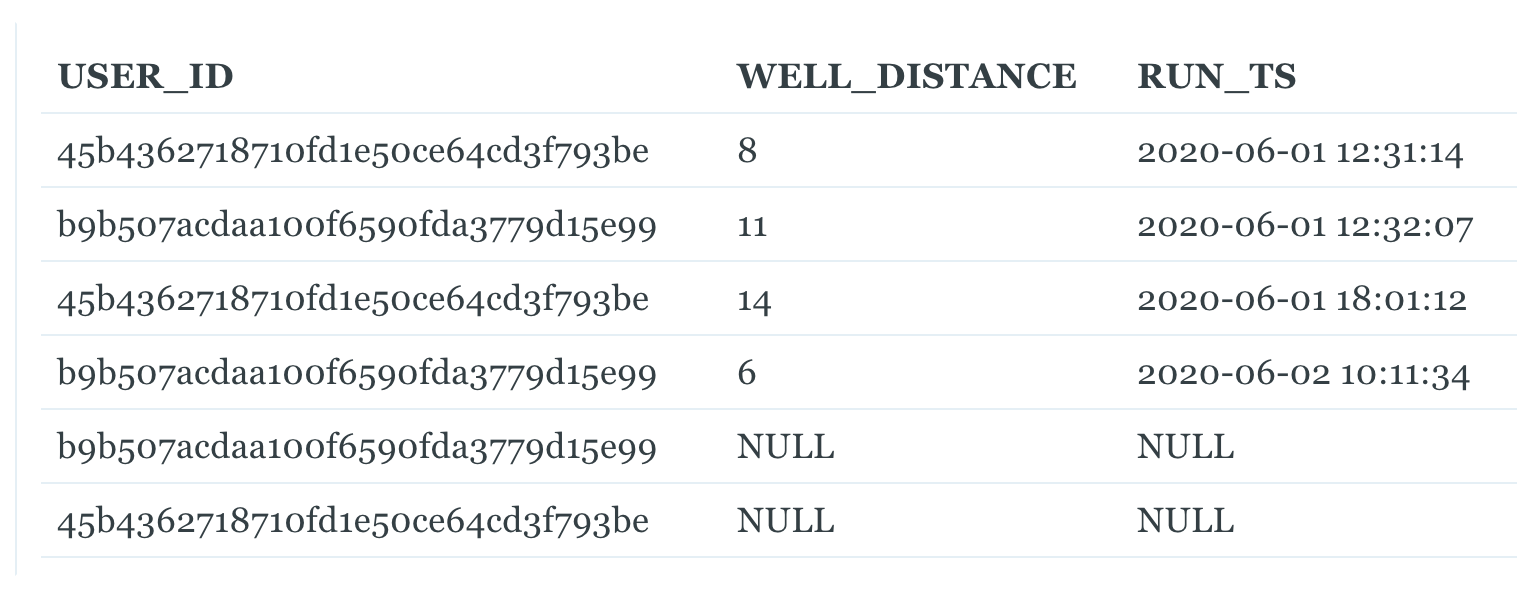
Something happened with our ETL load on June 3rd, and it couldn’t get data correctly. To debug this issue, it would be helpful to identify the rows from the staging table that this data came from. If we did not know any better, we might be tempted to say that the garbled rows came from any RUN_TS after 2020-06-02, but then we fail to include Jill’s backfilled record. How can we accurately identify the batch of data in WELL_RUN that went wrong?
Thanks to the magic of foreshadowing, you know that the answer to these problems is to use LOAD_DATE. First let’s review the problems we have:
- Incremental loads are unreliable with backfilled or updated data
- There is no easy way to trace batches of data through our data warehouse
Here’s how it can help: first we change our ETL job that loads the staging table, WELL_RUN, to include a UTC timestamp for every batch of data:
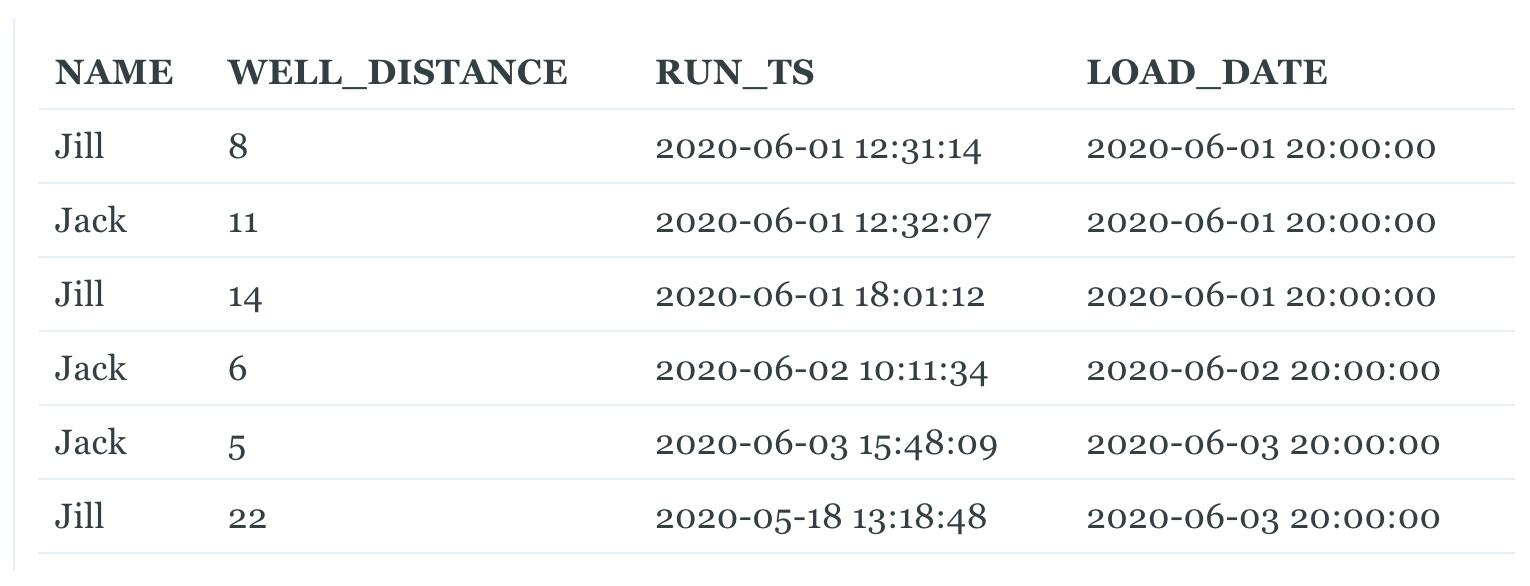
This simple change solves our first problem. Any table we load from WELL_RUN can reliably use LOAD_DATE to incrementally load data. Because LOAD_DATE is a system-generated timestamp, it will always move forward and never be backdated. As a bonus, we do not have to worry about timezone differences between different sources of data.
There’s another benefit to LOAD_DATE that will solve our second issue. In addition to acting as a system-timestamp, it also serves as a kind of batch ID. The data that came together in one ETL run will be given the same LOAD_DATE, and so we can trace any batch of data through our entire data warehouse by keeping LOAD_DATE around in future tables. Here, for instance, is our botched fact table with the LOAD_DATE from WELL_RUN:
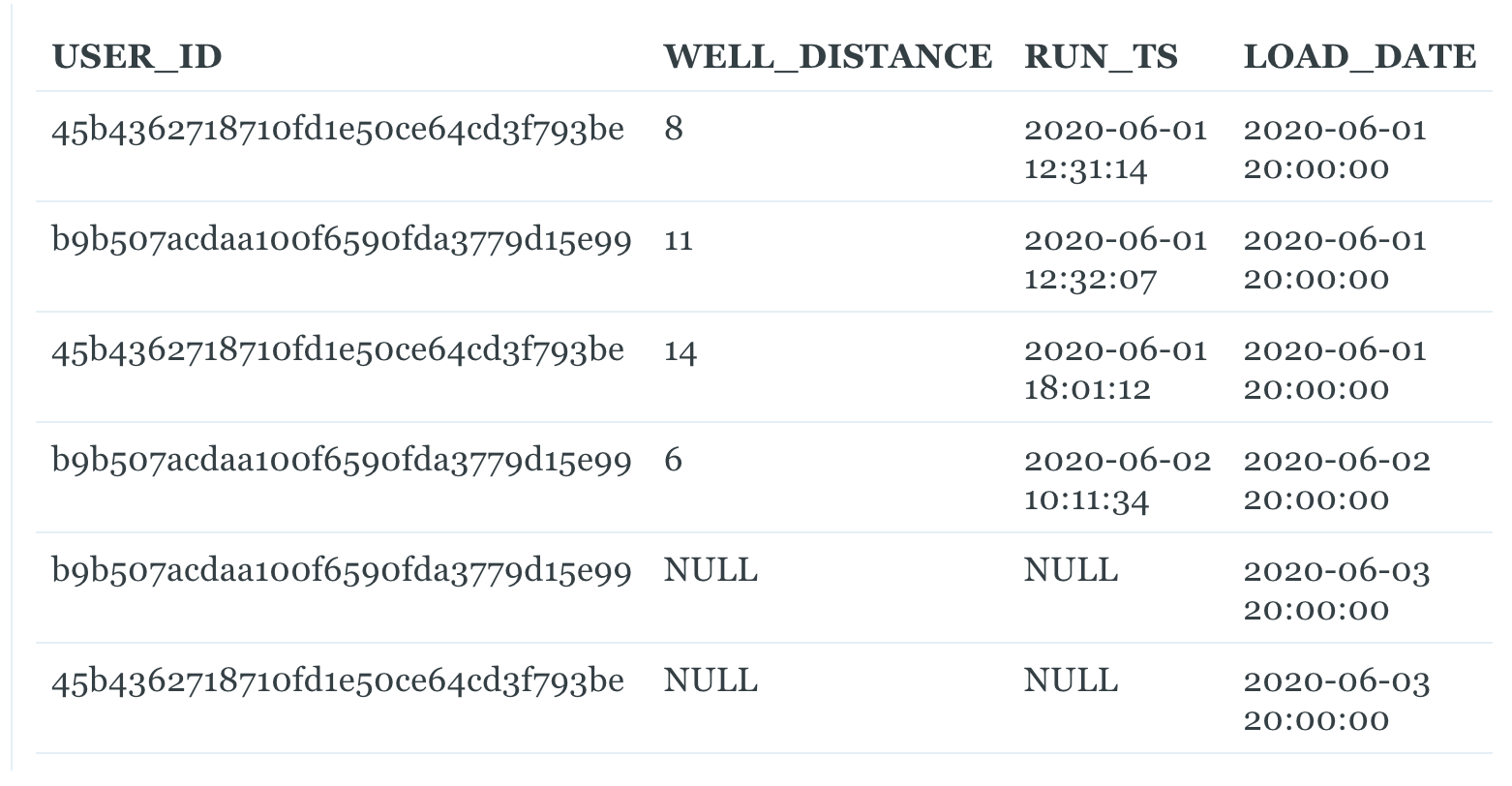
Because we keep LOAD_DATE in our tables, we know exactly which set of data became garbled, and can reload the set of data from WELL_RUN with a LOAD_DATE of ‘2020-06-03 20:00:00’. In general, persisting a LOAD_DATE through the warehouse makes debugging and auditing data much simpler.
Conclusion
And that is all you need - some timestamps and hashes. If these simple concepts are implemented elegantly and consistently, they can make your data model more robust with little effort.
Like I alluded to earlier, these techniques helped our dimensional model tackle bigger versions of the examples above. We have sped up our ETL schedule thanks to using MD5 hashes for surrogate keys. When we build dimensions out of user form inputs, we can handle some typos with a touch more grace. Once data hits our staging layer, we can incrementally load from there without worrying about the underlying data. Differing time zones and backdating are just quirks of the data instead of opportunities for data loss. If these challenges sound familiar, then maybe consider mixing in a pinch of Data Vault to your model too.

