
By Andrew Gauci, Technical Architect
Apache Kafka is a powerful message streaming platform, supporting a wide range of use cases; from publish-subscribe semantics, to distributed queues, to an event sourced data store (amongst others). Initially developed by LinkedIn, the architecture boasts impressive performance, is inherently robust against partial failure (driven by network outages, or otherwise), and has been adopted by an impressive number of heavyweights including Spotify, Netflix and Uber. Keeping the above in mind, it is easy for an application developer to fall into one of the most pervasive network fallacies, by assuming that Kafka is a reliable piece of remote infrastructure which will always be available. However, Kafka - as with any resource available over a network - can and will be intermittently unavailable to the application. If an application is to be truly built for robustness, it must be able to isolate failure, gracefully respond during periods of resource outage, and recover once the downstream component is available once more (a sentiment emphasised in the reactive manifesto).
Here at Yieldstreet, we have also fallen into the trap highlighted above. Taking a step back, our microservice-based architecture relies heavily on Kafka, both serving as the backbone for the propagation of events across the platform, as well as acting as a distributed event log and source of truth for services which focus on availability. Over the past months, our architecture experienced network blips within our internal network, resulting in intermittent network partitions and unavailable resources (once again, highlighting the need to build reactive applications). Although our services mostly recovered from such outages, they were unable to re-connect to Kafka long after the blip, and only recovered after the affected services were restarted.
So, what did we learn from this experience? Firstly, although the choice of leveraging Kafka brings with it a wealth of opportunity, it is just as critical for the application developer to consider how the application will react to its unavailability. There are two parts to this equation, namely (i) deciding how the application will react during outage, and (ii) ensuring that the application reconnects once Kafka is reachable again. The first part of the equation is beyond the scope of this article, and entails its own set of design decisions. For instance, here at Yieldstreet we opted to fail the ongoing process if the event cannot be published in cases where Kafka acts as a source of truth. Our Lagom based services took a different approach, persisting event logs in a separate data store, and applying ReadSideProcessors to consume persisted events and asynchronously publish them to Kafka. In doing so, an event is not marked as processed unless the application is sure that it has been published on Kafka. For full disclosure, one still needs to contend with the possibility of the data source’s unavailability, should the latter solution be applied. It is rarely acceptable to simply ignore the failure, since this leads to a loss of data integrity.
Ensuring Reconnection Post Failure
The remainder of this article details the solution adopted by Yieldstreet for the second part of the problem, namely ensuring that the application gracefully reconnects to Kafka once it is available to the application once more. This solution is based around the use of Alpakka Kafka library, which abstracts the interaction between Kafka and the rest of our actor-based microservices. Crucially, by leveraging these technologies this allows our microservices to abstract events happening over Kafka as a continuous flow of data, bringing with it advantages associated with stream-based semantics. As will be shown in further detail below, these technologies do provide the tools to ensure robustness in the face of failure, but are dependent on appropriate configuration and implementation.
Consumers
The creation of consumers via Akka Streams is described here. From an implementation perspective, the following points are required:
- Wrap the Akka stream subscription within an actor, and subscribe on actor creation/preStart. If an Akka stream is created, ensure that the stream is mapped to a Control object (or a subclass such as DrainingControl). This provides the necessary machinery allowing the application to observe - and react - to stream completion.
- Using the Control object, register notification of the stream's completion via isShutdown, and react to the stream's completion by sending a custom message to the same actor which curates the stream/subscription. For example, assuming a custom StreamShutdown object:
control.isShutdown().thenRun(() -> self.tell(StreamShutdown.getInstance()))- Ensure that the actor reacts to the stream shutdown (in this case, by listening to
StreamShutdown)by re-creating the stream, thus ensuring a re-connection attempt upon failure.
The following configuration is also necessary to ensure stream termination upon repeated failure by the underlying KafkaConsumer to communicate with the remote broker. Failure to add this configuration can result in a dangling stream which does not consume events post re-connection, but does not fail either.
akka {
...
kafka {
...
consumer {
...
connection-checker {
# Flag to turn on connection checker
enable = true
# Amount of attempts to be performed after a first connection failure occurs
max-retries = 3
# Interval for the connection check. Used as the base for exponential retry.
check-interval = 1s
# Interval multiplier for backoff interval
backoff-factor = 2.0
}
}
}
}The above configuration leverages an internal Akka stream polling mechanism which continuously monitors the stream's connectivity with the broker, and ensures stream failure after repeated failed attempts. This configuration coupled with the actor's reaction to stream failure ensures eventual recovery.
Producers
Producing events via streams is documented here. Should we require time bounded producer event delivery with notification of failure, a similar approach to that taken by consumers is required:
- Wrap the producer’s Akka stream within an actor.
- Register a listener to the stream's completion. The implementation of such a listener varies by the type of source used. For example, if a SourceQueueWithComplete is used, register a listener on the CompletionStage returned by the queue's offer method, or via the queue's watchCompletion. Irrespective of the choice made, a message should be sent to the same actor wrapping the stream via a custom message:
queue.watchCompletion()
.whenComplete((res, ex) -> self.tell(StreamShutdown.getInstance()));- Once failure is detected by the actor (by listening to the custom message notifying stream termination), the actor can decide on the appropriate response. If there is a pending HTTP response, this can be failed. A backup storage can also be used to persist this event. Retrying is also an option. Irrespective of the choice made, the stream should be re-created in preparation for the next event to be published.
Producer configuration is more nuanced, since the producer is governed by various timeouts depending on its internal state.
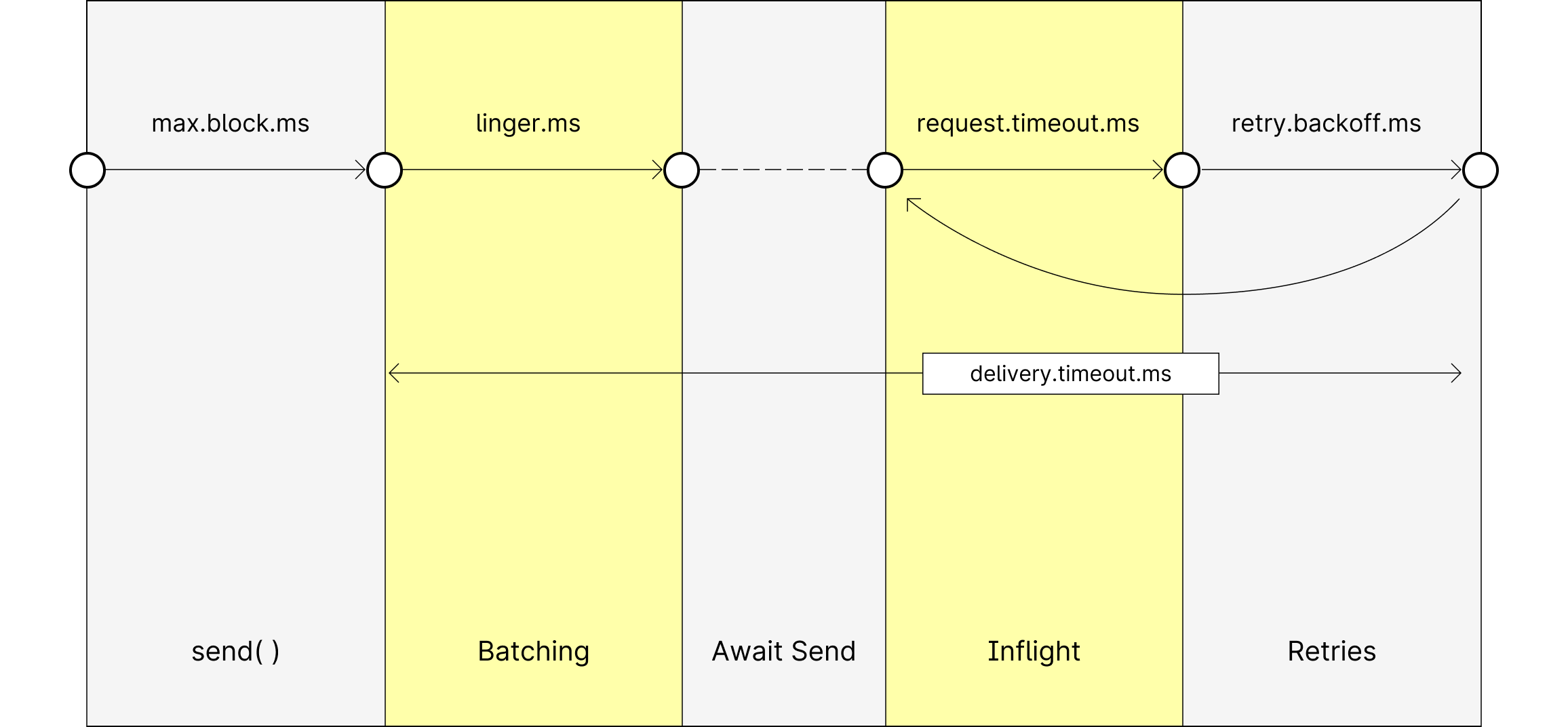
The KafkaProducer periodically retrieves the broker metadata, depending on the metadata's availability and staleness. This initial metadata retrieval attempt is blocking, and is governed by max.block.ms. Should the producer have valid broker metadata (and has skipped the batching phase governed by linger.ms), it will start its delivery attempts. The event delivery procedure duration is subsequently governed by one global delivery.timeout.ms configuration. The following configuration ensures producers behave in a time-bound fashion of 1 minute when attempting to publish events (and can be adjusted as necessary):
akka {
...
kafka {
...
producer {
...
# Ensures cleanup of producers on stream failure.
close-on-producer-stop = true
kafka-clients {
# Ensure that Kafka's inbuilt idempotent retry mechanism is
# turned off, allowing the application to react to failure
enable.idempotence = false
# Ensure metadata retrieval and individual produce attempts
# do not exceed a minute
max.block.ms=60000
delivery.timeout.ms=60000
# For an individual delivery attempt, wait 15s before
# considering the attempt as failed, and wait a further
# 5s as backoff. Attempt delivery 4 times, exceeding
# the total time set for the global delivery effort.
retries = 4
request.timeout.ms = 15000
retry.backoff.ms=5000
# Should disconnection between the KafkaProducer and
# broker be detected, the producer will attempt to
# re-establish connection, starting with a rate of
# once every 50ms, and increasing up to 1s using an
# exponential backoff.
reconnect.backoff.ms=50
reconnect.backoff.max.ms=1000
# If order delivery is important, set this config to 1
# ensuring that event ordering is not lost during retries.
max.in.flight.requests.per.connection=1
...
}
}
}
}
As is the case with consumers, the use of actors which react to stream failure coupled with configuration which time bounds publishing efforts ensures that the application reacts to Kafka downtime.
Conclusions
The above article serves as an outline solution for ensuring that an Actor-based application leveraging Kafka via Akka streams will gracefully reconnect when faced with Kafka unavailability. The article intentionally leaves some room for manoeuvre in terms of the application’s actor implementation. Neither should this article be interpreted as providing the only solution for this problem - other equally valid solutions may be possible. Having said that, this solution has proven to be robust at Yieldstreet against downtime, both in case of short bursts of unavailability, as well as during lengthier downtime. Two last points to keep in mind;
- Should producers be required to continuously attempt to deliver the same message on failure (as opposed to reacting to failure), Kafka's enable.idempotence feature can be explored. The advantage with using this feature is that Kafka takes care of dropping duplicate events during delivery re-attempts internally. Note that using this feature will not allow the application to react to produce failures, and can still lead to event loss if the application shuts down before all pending events are published.
- Should the proposed producer solution be applied which retries message delivery during downtime (i.e. outside of Kafka's inbuilt idempotency feature), it is improbable - but possible - that multiple copies of the same event are published. It is therefore a requirement of downstream consumers to process events in idempotent fashion, i.e. skipping events which have already been processed. To achieve this, all events published should admit an update ID which uniquely identifies the update to facilitate idempotency during consumption. This suggestion of uniquely identifying updates and ensuring idempotency on the consumer’s side is a foundational solution for ensuring exactly-once semantics across distributed applications, and should be considered regardless.
